 StableToolBench
StableToolBench
Large Language Models (LLMs) have witnessed remarkable advancements in recent years, prompting the exploration of tool learning, which integrates LLMs with external tools to address diverse real-world challenges. Assessing the capability of LLMs to utilise tools necessitates large-scale and stable benchmarks.
However, previous works relied on either hand-crafted online tools with limited scale, or large-scale real online APIs suffering from instability of API status. To address this problem, we introduce StableToolBench, a benchmark evolving from ToolBench, proposing a virtual API server and stable evaluation system. The virtual API server contains a caching system and API simulators which are complementary to alleviate the change in API status. Meanwhile, the stable evaluation system designs solvable pass and win rates using GPT-4 as the automatic evaluator to eliminate the randomness during evaluation. Experimental results demonstrate the stability of StableToolBench, and further discuss the effectiveness of API simulators, the caching system, and the evaluation system.
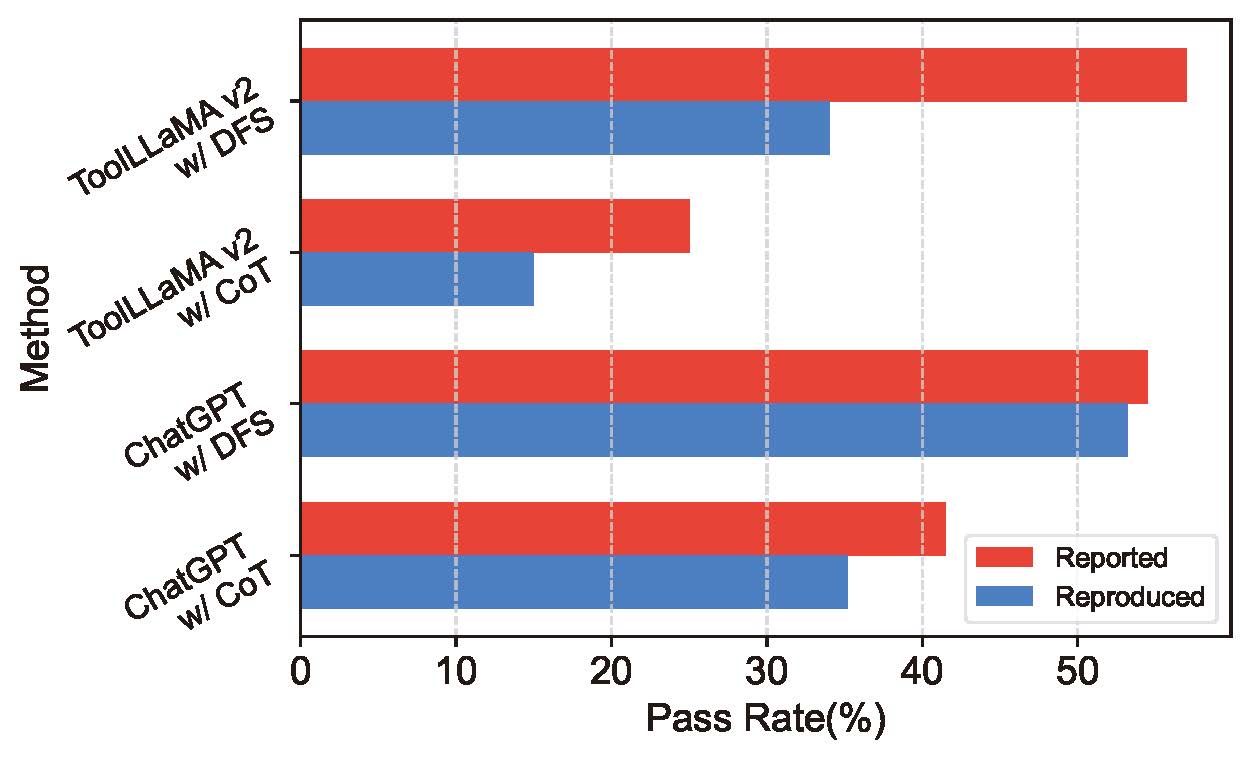
Benchmarks are designed to consistently evaluate the performance of various models over time. To test this consistency of ToolBench, we reproduce the model performances and record any variations. As depicted in Figure 1, a notable decline in the performance of all methods over time is observed, which raises concerns about the stability of ToolBench as a benchmark. Click here to overview the detailed analysis of the impacts of API status and the evaluation system in ToolBench on stability of the benchmark.
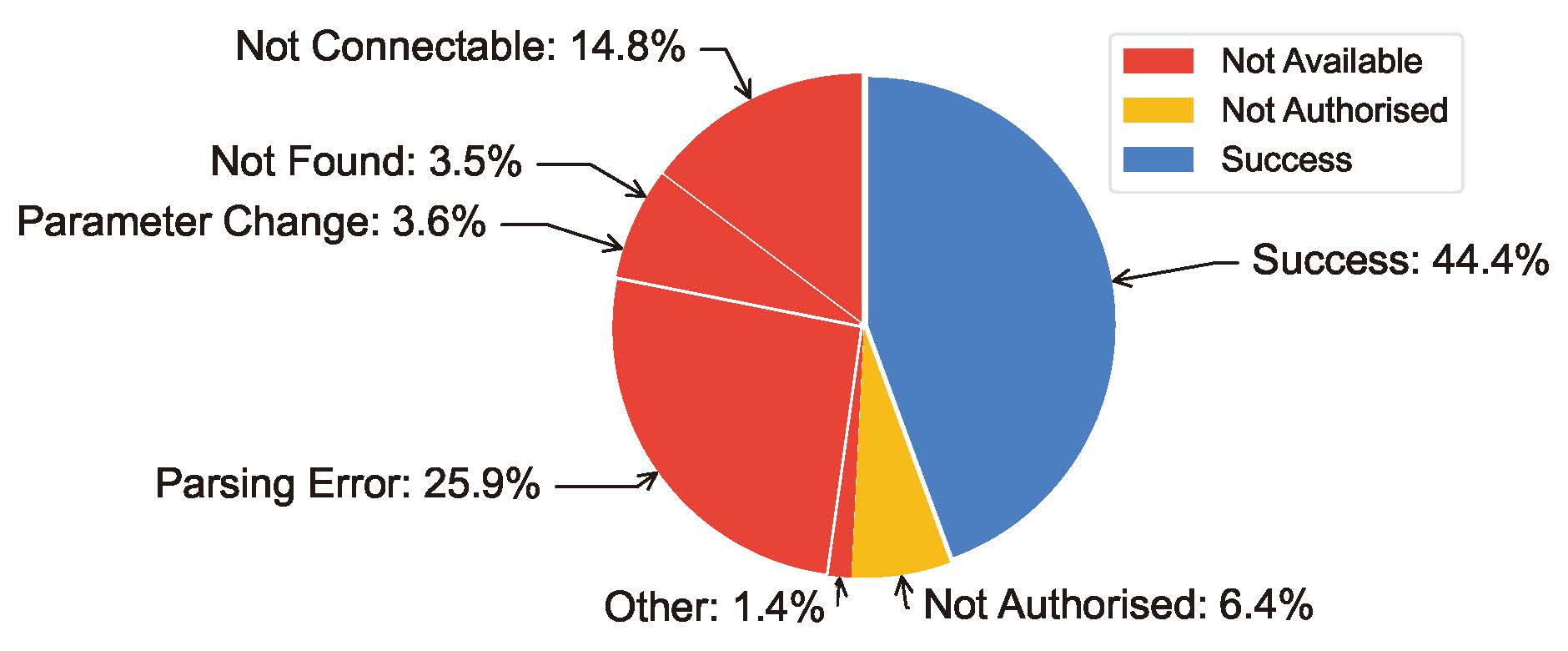
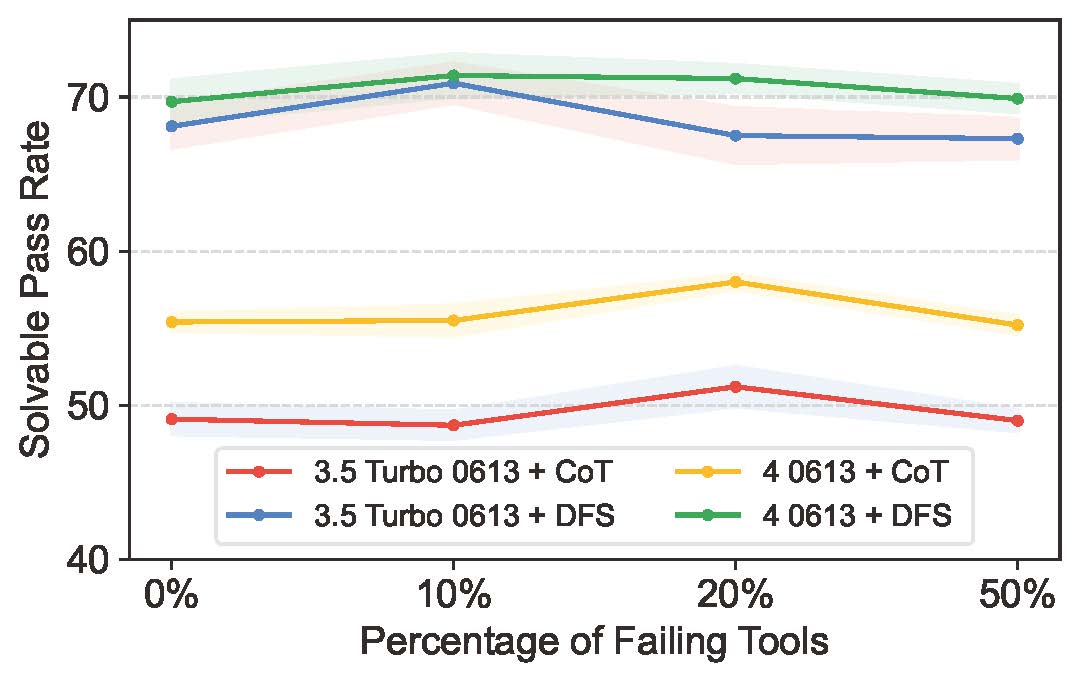
ToolBench exihibits significant instability on the API status (Figure 1). This instability was primarily due to issues such as expired APIs, network issues, or failed authentication. Only 44.4% of API calls were successful, with the rest being mostly unavailable due to various errors, some not authorized, and others suffering from parsing errors and parameter changes. This instability in API status led to considerable variability in model performance assessments and had a significant impact on the stability of the benchmark (Figure 2). When APIs failed or behaved unpredictably, it directly affected the tools' ability to function correctly and consistently, thereby impacting the effectiveness of the tools and the overall reliability of the benchmark
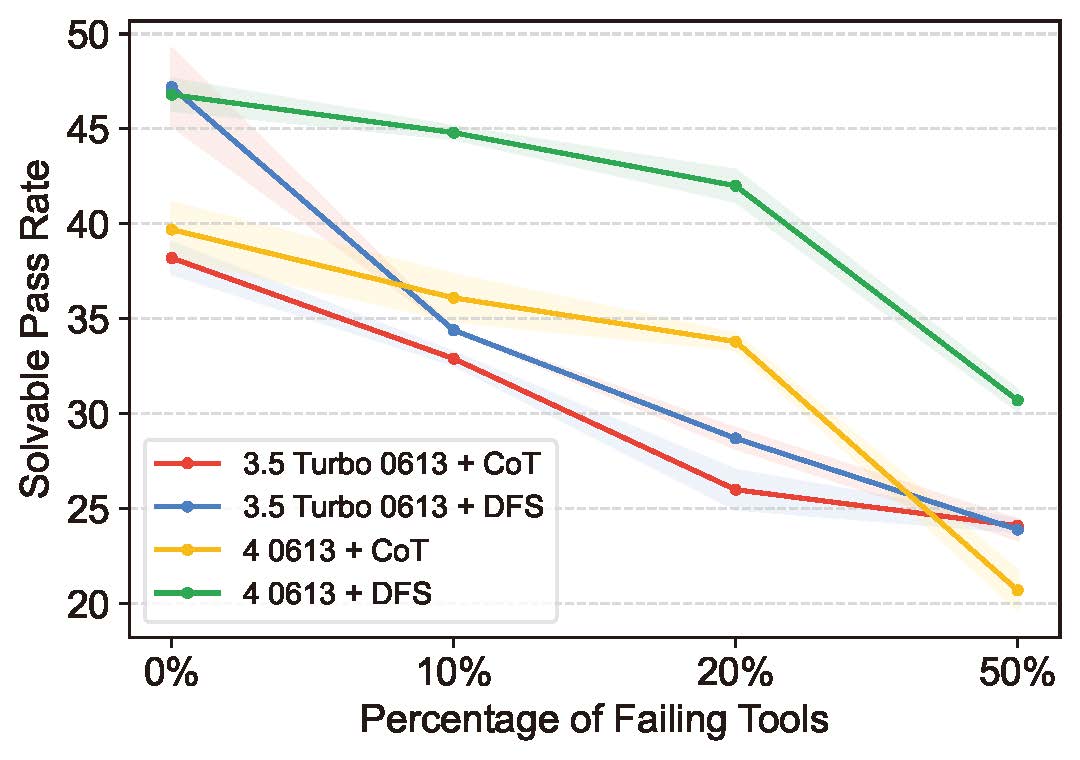
The evaluation metrics used in ToolBench, such as Pass Rate (PR) and Win Rate (WR), are subject to randomness, particularly when dealing with tasks labeled as "unsolvable" or "unsure". This randomness contributes to inconsistencies in model evaluations. For example, despite using the same tasks, the results varied significantly between different strategies like Chain-of-Thought (CoT) and Depth First Search (DFS), and the discrepancy in evaluation was noted to be a problem.
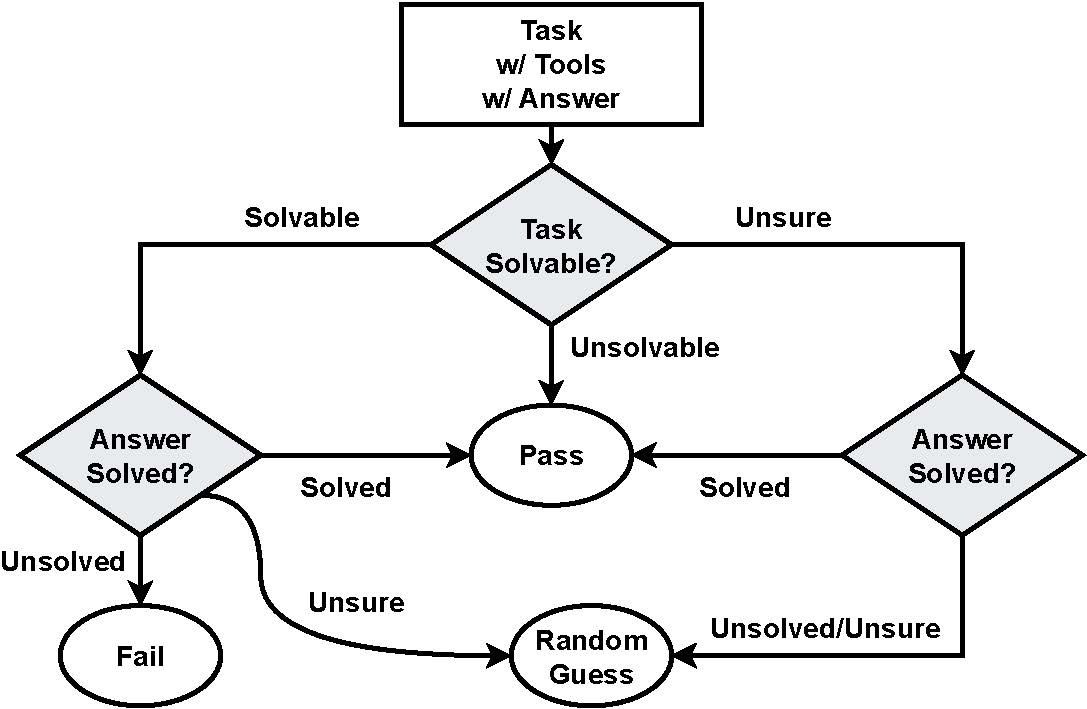
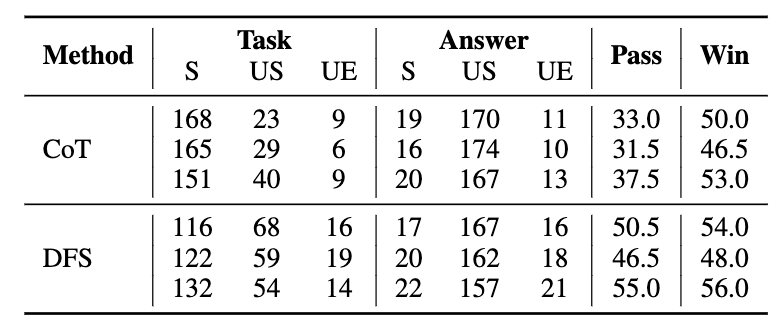
GPT-3.5-Turbo-0613 with CoT and DFS. S, US, and UE indicate solvable (solved), unsolvable (unsolved), and unsure. Pass and Win denote pass rate and win rate, respectively.
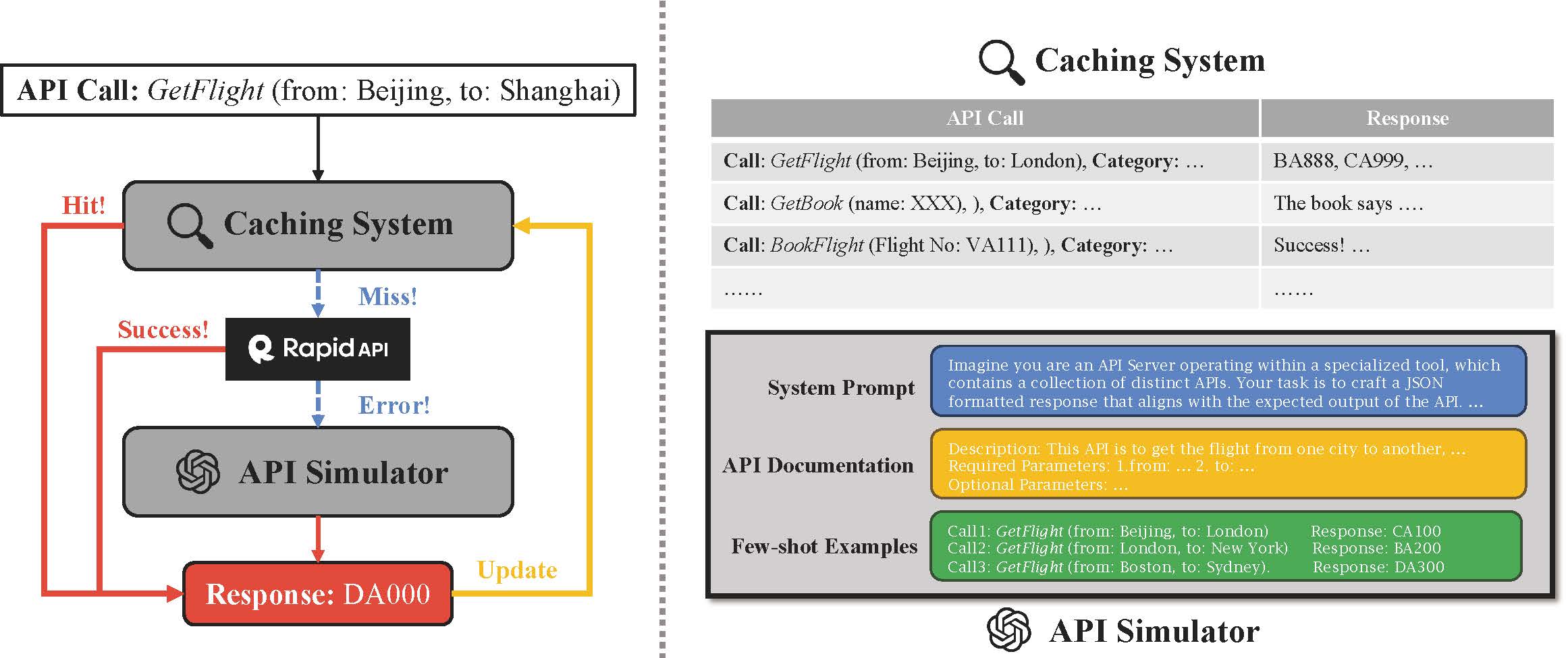
To stabilise the API server, we propose to use the virtual API server. It comprises two primary components: a caching system and an API simulator. The caching system stores responses from all API calls, ensuring consistency and reducing latency. It's populated with data from both the training and test phases and continuously updated to maintain scalability and quality. The API simulator, powered by a large language model (gpt-4-turbo), simulates API responses that aren't in the cache or are unavailable. It utilizes documentation and real API call examples as few-shot prompts to ensure the simulated responses closely mimic real API behavior. Together, these components work under specific calling rules, initially checking the cache for a response before attempting a real API call and, if necessary, resorting to the simulated response. This integrated approach aims to balance stability and reality in API behaviors, significantly enhancing the benchmark's reliability and effectiveness.
Solvable Tasks Filtration. Since the solvablility of tasks in original ToolBench induces siginificant instability, we filter out the unsolvable tasks in advance. This process is executed using GPT-4, Gemini Pro, and Claude 2. Each task from the dataset is evaluated by these models to determine its solvability through majority voting. A task is classified as solvable if it provides all the necessary and valid information required for completion and can be resolved with the available tools. Human evaluation shows that these models can effectively filter out unsolvable tasks, ensuring the stability of the benchmark.
| I1 Instruction | I1 Category | I1 Tool | I2 Instruction | I2 Category | I3 Instruction | Total | |
|---|---|---|---|---|---|---|---|
| Full | 200 | 200 | 200 | 200 | 200 | 100 | 1100 |
| Solvable | 163 | 153 | 158 | 106 | 124 | 61 | 765 |
Table 1: Summary of Task Statistics before and after filtration
Metrics (SoPR and SoWR). Due to the limitation of gpt-3.5-turbo-16k in tool learning, we uniformly adopt gpt-4-turbo-preview as the automatic evaluator.
SoPR is in essence PR with all tasks solvable and only assesses the answers using the same prompt in ToolBench. The evaluator assigns outcomes of answers categorised as Solved, Unsolved, or Unsure, which respectively contribute scores of 1, 0.5, and 0 to the overall SoPR calculation.
As for SoWR, when one is solved and the other is unsolved, the solved one wins.
Under other circumstances, gpt-4-turbo-preview will be used to make a win-lose decision.
| Method | I1 Instruction | I1 Category | I1 Tool | I2 Category | I2 Instruction | I3 Instruction | Average |
|---|---|---|---|---|---|---|---|
| GPT-3.5-Turbo-0613 (CoT) | 52.2±1.1 | 47.3±0.6 | 53.6±1.3 | 42.5±2.1 | 35.8±2.0 | 48.1±0.8 | 46.6±1.3 |
| GPT-3.5-Turbo-0613 (DFS) | 60.3±1.3 | 66.2±1.2 | 67.1±0.0 | 59.1±0.4 | 51.3±1.2 | 73.8±2.3 | 63.0±1.1 |
| GPT-4-0613 (CoT) | 45.5±0.4 | 57.4±0.3 | 48.8±0.7 | 43.0±0.7 | 46.5±0.9 | 48.1±1.5 | 48.2±0.8 |
| GPT-4-0613 (DFS) | 57.3±0.6 | 57.3±0.3 | 60.9±1.0 | 57.9±1.0 | 51.3±0.8 | 66.4±2.4 | 58.5±1.0 |
| ToolLLaMA v2 (CoT) | 32.3±1.0 | 40.3±0.8 | 36.7±0.5 | 34.7±0.7 | 25.2±0.4 | 33.9±1.5 | 33.9±0.8 |
| ToolLLaMA v2 (DFS) | 44.5±0.9 | 49.6±1.3 | 48.9±2.7 | 50.8±1.1 | 31.9±1.9 | 53.6±2.0 | 46.6±1.7 |
| GPT-3.5-Turbo-1106 (CoT) | 50.4±0.5 | 45.1±1.4 | 50.8±0.3 | 48.7±0.8 | 42.1±0.4 | 55.7±0.0 | 48.8±0.6 |
| GPT-3.5-Turbo-1106 (DFS) | 62.8±0.3 | 63.9±1.2 | 65.6±0.3 | 56.5±0.7 | 56.9±1.2 | 67.2±1.3 | 62.2±0.8 |
| GPT-4-Turbo-Preview (CoT) | 52.8±1.3 | 56.6±0.9 | 51.9±0.5 | 51.9±1.0 | 52.8±0.8 | 52.5±0.0 | 53.1±0.8 |
| GPT-4-Turbo-Preview (DFS) | 59.2±0.5 | 61.7±0.7 | 65.7±1.0 | 55.6±0.6 | 55.2±0.4 | 66.1±4.3 | 60.6±1.3 |
Table 2: Solvable Pass Rate scores. In this experiment, we run all models once, evaluate three times and take the average results.
| Method | I1 Instruction | I1 Category | I1 Tool | I2 Category | I2 Instruction | I3 Instruction | Average |
|---|---|---|---|---|---|---|---|
| GPT-3.5-Turbo-0613 (DFS) | 60.7 | 67.3 | 59.5 | 63.2 | 62.1 | 75.4 | 64.7 |
| GPT-4-0613 (CoT) | 54.6 | 58.8 | 58.2 | 75.5 | 60.5 | 62.3 | 61.7 |
| GPT-4-0613 (DFS) | 62.6 | 62.7 | 58.2 | 74.5 | 62.9 | 67.2 | 64.7 |
| ToolLLaMA v2 (CoT) | 31.3 | 28.1 | 33.5 | 35.8 | 33.9 | 24.6 | 31.2 |
| ToolLLaMA v2 (DFS) | 44.8 | 45.8 | 44.3 | 59.4 | 41.1 | 50.8 | 47.7 |
| GPT-3.5-Turbo-1106 (CoT) | 47.2 | 47.7 | 44.9 | 50.9 | 54.0 | 62.3 | 51.2 |
| GPT-3.5-Turbo-1106 (DFS) | 55.8 | 53.6 | 51.9 | 68.9 | 59.7 | 68.9 | 59.8 |
| GPT-4-Turbo-Preview (CoT) | 71.2 | 77.1 | 61.4 | 79.2 | 71.8 | 67.2 | 71.3 |
| GPT-4-Turbo-Preview (DFS) | 73.0 | 75.2 | 68.4 | 77.4 | 66.9 | 60.7 | 70.2 |
Table 3: Solvable Win Rate scores. We run all models once against GPT-3.5-Turbo-0613 + CoT and evaluate three times. We follow the ToolBench implementation to take the most frequent result for each query during evaluation.
@misc{guo2024stabletoolbench,
title={StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models},
author={Zhicheng Guo and Sijie Cheng and Hao Wang and Shihao Liang and Yujia Qin and Peng Li and Zhiyuan Liu and Maosong Sun and Yang Liu},
year={2024},
eprint={2403.07714},
archivePrefix={arXiv},
primaryClass={cs.CL}
}